Python Data Manipulation Explained

When data manipulation and preparation account for up to 80% of data analysis projects, mastering data cleansing techniques that take raw data to a final product for analysis as efficiently as possible is essential for any project’s success.
To expedite this process, many teams turn to Python data manipulation and one of its most popular libraries, Pandas. In fact, Pandas is used by Google, Facebook, JP Morgan, and nearly every other major company that analyzes data today.
And it’s easy to see why…
With 68% of all data scientists using Python, this makes it the most popular programming language in the industry and the most in-demand in the US.
2020 is expected to see a 28% increase in data scientists, with over 364,000 jobs opening up in this sector. And with average salaries hovering around $120,000 it’s also one of the most lucrative skills to have on your resume.
Performing data manipulation tasks with Python library Pandas makes it easier for data professionals to achieve better results, increase productivity, and free up more time for problem-solving, which gives teams more time to extract deeper and more accurate insights effectively.
And since Python is likely part of your organization’s tech stack to begin with, and many of your team members are already familiar with the language, using Python data manipulation and Pandas is a natural choice.
While there are several Python tools that are suitable for Extract, Transform and Load procedures, like Airflow, PySpark, Bonobo, Luigi and more, Pandas is one of the most widely utilized libraries in data science today. And when building ETL data science tools, many data scientists choose Pandas first.
Data Manipulation in Python

In data science, data quality is king, which is why so much time is spent cleaning, wrangling and ensuring its integrity.
But in the real world, data is often incredibly messy, and data manipulation aims to address its common pitfalls:
- Incomplete or missing data. Misformatted and mistyped, wrong or corrupted values.
- Non-availability, no appropriate means of collection, lack of validation or human errors.
But data preparation isn’t only about cleaning and quality. Data scientists must also carefully transform their data into a form that’s usable for their end goals.
Much like cleaning, this can take on many forms. This could mean enriching data by merging different sources or applying different Machine Learning algorithms for classification or predictions and don’t forget about dealing with regular data updates.
This is where ETL data science procedures and data engineers come in handy.
ETL Procedures and Pandas
Short for Extract, Transform and Load, ETL are three database functions that when combined form to create one tool.
- Extract is the process of reading data from a database.
- Transform is the process of converting the extracted data into another format to be placed into another database.
- Load is the process of writing the data into the target database.
ETL is one of the most crucial elements of Business Intelligence and Machine Learning processes and systems.
And while SQL may be able to handle simple data transformations, like one-to-one column mappings and calculating additional columns, Python is much better suited for more complex tasks like row deduplication, aggregating columns.
If you’re already comfortable with Python, using Pandas to write ETLs is a natural choice for many, especially if you have simple ETL needs and require a specific solution. In this care, coding a solution in Python is appropriate.
Pandas, in particular, makes ETL processes easier, due in part to its R-style dataframes. When you need to quickly extract data, clean and transform it, and write your dataframe to CSV, SQL database or Microsoft Excel, Pandas is an effective tool.
Data Scientist vs Data Engineering
If data preparation is where you excel, then a role as a Data Engineer might be appropriate for you.
While Data Scientists apply different approaches like statistics and Machine Learning to solve critical business problems, Data Engineers are responsible for preparing the data infrastructure to be analyzed by Data Scientists and Data Analysts.
A Data Engineer’s daily work involves designing, building, managing and integrating various sources of data and then writing complex queries to ensure accessibility and optimization of their company’s big data ecosystem.
As a Data Engineer, you’ll be responsible for three main duties:
- To ensure that the data pipeline, including data acquisition and processing, is running smoothly.
- To serve the needs of internal customers and departments, ie: Data Analysts and Data Scientists.
- To control the cost of storing and moving data.
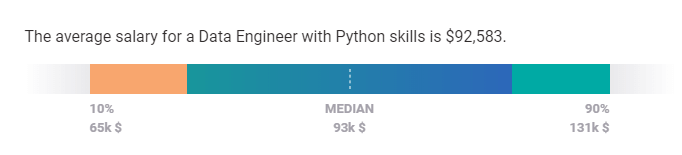
The average Python Engineer earns an average salary of $92,388, Payscale reports. But to qualify, you must have the critical skills. These include “Python, SQL, R and ETL methodologies and practices,” says Paul Lappas, co-founder and CEO of Intermix, a performance monitoring tool for data teams.
And while a passion for processing data is an obvious pre-requisite, you will also need to possess the following skills and attributes to excel in any data engineering role:
- Attention to detail: when building a pipeline, data quality is extremely important.The insights that external teams will only be as good as the quality and integrity of the data that flows through your data pipeline.
- Clean design principles: an effective data engineer prioritizes clean and simple pipeline design.
- Excellent communication skills: Getting the right data moving from multiple locations involves speaking with people and understanding different infrastructures before designing an effective ecosystem.
- An appreciation for back-end systems: much of a Data Engineer’s work deals with back-end systems.
- A desire for constant learning: while this applies to most AI-related roles, a competent Python engineer must keep pace with emerging libraries, tools and frameworks in the field.
So how do you gain the experience when you’re making a career transition, or simply don’t have the necessary formal education? “If you have only a bachelor’s degree and want to get on a data engineering team, I recommend you make a personal project that shows what you can do, not just what you can talk about,” says Data Engineer and managing director of the Big Data Institute.
If you can’t wait to dive right into data manipulation and Pandas then our latest course Python for Data Manipulation allows you to go hands-on with the tools and techniques used by global leaders. Enroll today and add data manipulation projects to your portfolio in under one week.



