The Complete Guide to Perceptron Algorithm in Python

Artificial neural networks are highly used to solve problems in machine learning. The perceptron algorithm is the simplest form of artificial neural networks. Machine learning programmers can use it to create a single Neuron model to solve two-class classification problems. Such a model can also serve as a foundation for developing much larger artificial neural networks. In this article, I will be showing you how to create a perceptron algorithm Python example.
What is a Perceptron?
The concept of the perceptron in artificial neural networks is borrowed from the operating principle of the Neuron, which is the basic processing unit of the brain.
The Neuron is made up of three major components:
- Dendrites
- Cell body
- Axon
The following figure shows the structure of a Neuron:
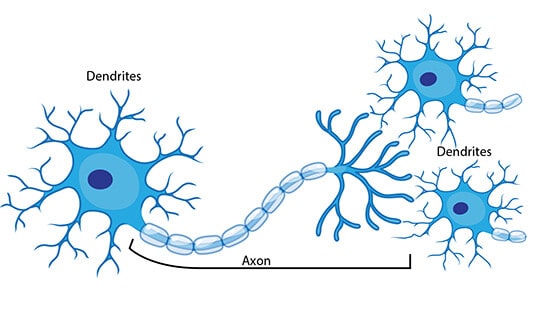
The work of the dendrites is to carry the input signals.
The processing of the signals is done in the cell body, while the axon carries the output signals.
The Neuron fires an action signal once the cell reaches a particular threshold.
The action of firing can either happen or not happen, but there is nothing like “partial firing.”
Just like the Neuron, the perceptron is made up of many inputs (commonly referred to as features).
The inputs are fed into a linear unit to generate one binary output.
Due to this, the perceptron is used to solve binary classification problems in which the sample is to be classified into one of two predefined classes.
How the Perceptron Algorithm Works
The perceptron is made up of the following parts:
- Input values/One input layer
- Weights and Bias
- Net Sum
- Activation Function
These are shown in the figure given below:
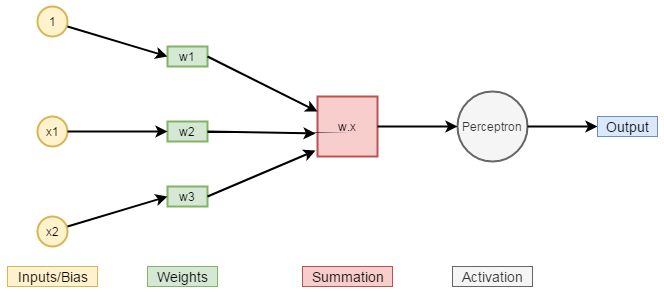
The perceptron takes in a vector x as the input, multiplies it by the corresponding weight vector, w, then adds it to the bias, b.
The result is then passed through an activation function.
You must be asking yourself this question…
“What is the purpose of the weights, the bias, and the activation function?”
Let me show you…
The weights are used to show the strength of a particular node.
The value of the bias will allow you to shift the curve of the activation function either up or down.
The activation function will help you to map input between the values that are required, for example, (-1, 1) or (0, 1).
Note that a perceptron can have any number of inputs but it produces a binary output.
But how do you take many inputs and produce a binary output?
First, each input is assigned a weight, which is the amount of influence that the input has over the output.
To determine the activation for the perceptron, we check whether the weighted sum of each input is below or above a particular threshold, or bias, b.
In our case, the weighted sum is:
1.w¹ + x1.w² + x2w³
If the weighted sum is equal to or less than the threshold, or bias, b, the outcome becomes 0.
If the weighted sum is greater than the threshold, or bias, b, the output becomes 1.
This formula is referred to as Heaviside step function and it can be written as follows:
f(x) = { x<=b : 0 , x>b : 1 }
Where x is the weighted sum and b is the bias.
Where is the Perceptron Algorithm used?
The Perceptron Algorithm is used to solve problems in which data is to be classified into two parts.
Because of this, it is also known as the Linear Binary Classifier.
Common Mistakes/Pitfalls when using the Perceptron Algorithm
Although the Perceptron algorithm is good for solving classification problems, it has a number of limitations.
First, its output values can only take two possible values, 0 or 1.
Secondly, the Perceptron can only be used to classify linear separable vector sets. According to the perceptron convergence theorem, the perceptron learning rule guarantees to find a solution within a finite number of steps if the provided data set is linearly separable.
Input vectors are said to be linearly separable if they can be separated into their correct categories using a straight line/plane. If the input vectors aren’t linearly separable, they will never be classified properly.
Next, you will learn how to create a perceptron learning algorithm python example.

Implementation of Perceptron Algorithm Python Example
You now know how the Perceptron algorithm works.
In this section, I will help you know how to implement the perceptron learning algorithm in Python.
We will use Python and the NumPy library to create the perceptron python example.
The Perceptron will take two inputs then act as the logical OR function.
Let’s start…
Import the Libraries
The following code will help you import the required libraries:
from numpy import array, random, dot
from random import choice
The first line above helps us import three functions from the numpy library namely array, random, and dot. The three functions will help us generate data values and operate on them.
The second line helps us import the choice function from the random library to help us select data values from lists.
Create a Step Function
The next step should be to create a step function.
This will act as the activation function for our Perceptron.
Remember that the Perceptron classifies each input value into one of the two categories, o or 1.
So, the step function should be as follows:
step_function = lambda x: 0 if x < 0 else 1
The function has been given the name step_function.
The function will return 0 if the input passed to it is less than 0, else, it will return 1.
Training Dataset
We can load our training dataset into a NumPy array.
This is shown below:
training_dataset = [
(array([0,0,1]), 0),
(array([0,1,1]), 1),
(array([1,0,1]), 1),
(array([1,1,1]), 1),
]
The training data has been given the name training_dataset.
The first two NumPy array entries in each tuple represent the two input values.
Each tuple’s second element represents the expected result.
The array’s third element is a dummyinput (also known as the bias) to help move the threshold up or down as required by the step function.
It always has a value of 1 so that its impact on the output may be controlled by the weight.
The Weights
Now that we have the inputs, we need to assign them weights.
We will choose three random numbers ranging between 0 and 1 to act as the initial weights.
We will use the random function of NumPy:
weights = random.rand(3)
Variable Initializations
We now need to initialize some variables to be used in our Perceptron example.
We will create a list named error to store the error values to be plotted later on.
If you’re not interested in plotting, feel free to leave it out.
We will also create a variable named learning_rate to control the learning rate and another variable n to control the number of iterations.
This is shown below:
error = []
learning_rate = 0.2
n = 100
Let’s reduce the magnitude of the error to zero so as to get the ideal values for the weights.
Remember that we are using a total of 100 iterations, which is good for our dataset.
For bigger and noisy input data, use larger values for the number of iterations.
Model Training
Now that everything is ready, it’s time to train our perceptron learning algorithm python model.
We will first get some random input set from our training data.
Next, we will calculate the dot product of the input and the weight vectors.
The result will then be compared with the expected value.
If the expected value turns out to be bigger, the weights should be increased, and if it turns out to be smaller, the weights should be decreased.
This is shown in the code given below:
for j in range(n):
x, expected = choice(training_dataset)
result = dot(weights, x)
err = expected – step_function(result)
error.append(err)
weights += learning_rate * err * x
The last line in the above code helps us calculate the correction factor, in which the error has been multiplied with the learning rate and the input vector.
This has been added to the weights vector in order to improve the results in the next iteration.
And that is what we need to train our Python Perceptron.
It can now act like the logical OR function.
Model Evaluation
Now that the model is ready, we need to evaluate it.
Just run the following code to see how it does the classification:
for x, _ in training_dataset:
result = dot(x, weights)
print(“{}: {} -> {}”.format(x[:2], result, step_function(result)))
The code should return the following output:
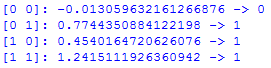
From the above output, you can tell that our Perceptron algorithm example is acting like the logical OR function.
Plot the Errors
The best way to visualize the learning process is by plotting the errors.
This is possible using the pylab library.
The pyplot module of the matplotlib library can then help us to visualize the generated plot.
Use the following code:
from pylab import ylim, plot
from matplotlib import pyplot as plt
ylim([-1,1])
plot(error)
plt.show()
The code will return the following plot:
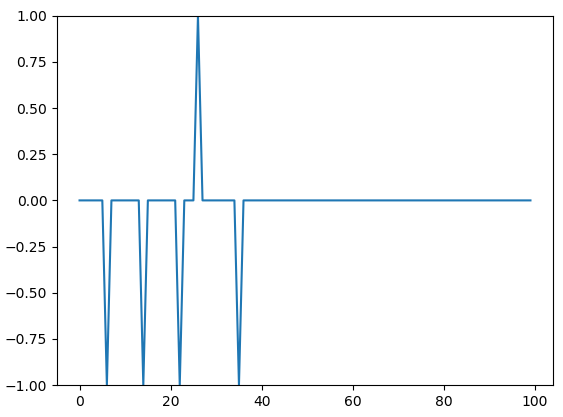
From the above chart, you can tell that the errors begun to stabilize at around the 35th iteration during the training of our python perceptron algorithm example.
Try to run the code with different values of n and plot the errors to see the differences.
And finally, here is the complete perceptron python code:
from numpy import array, random, dot
from random import choice
from pylab import ylim, plot
from matplotlib import pyplot as plt
step_function = lambda x: 0 if x < 0 else 1
training_dataset = [
(array([0,0,1]), 0),
(array([0,1,1]), 1),
(array([1,0,1]), 1),
(array([1,1,1]), 1),
]
weights = random.rand(3)
error = []
learning_rate = 0.2
n = 100
for j in range(n):
x, expected = choice(training_dataset)
result = dot(weights, x)
err = expected – step_function(result)
error.append(err)
weights += learning_rate * err * x
for x, _ in training_dataset:
result = dot(x, weights)
print(“{}: {} -> {}”.format(x[:2], result, step_function(result)))
ylim([-1,1])
plot(error)
plt.show()
Congratulations!
Your perceptron algorithm python model is now ready.
Conclusion:
This is what you’ve learned in this article:
- The perceptron algorithm is the simplest form of artificial neural networks.
- It can be used to create a single Neuron model to solve binary classification problems.
- The concept of the perceptron is borrowed from the way the Neuron, which is the basic processing unit of the brain, works.
- The perceptron takes in a vector x as the input, multiplies it by the corresponding weight vector, w, then adds it to the bias, b.
- The output is then passed through an activation function to map the input between the required values.
- It is easy to implement the perceptron learning algorithm in python.
To keep on getting more of such content, subscribe to our email newsletter now! And check out our data scientist learning path to gain career-changing knowledge you always needed.



